我们的研究
2024
To Preserve or To Compress: An In-Depth Study of Connector Selection in Multimodal Large Language Models
arXiv preprint
·
09 Oct 2024
·
arxiv:2410.06765
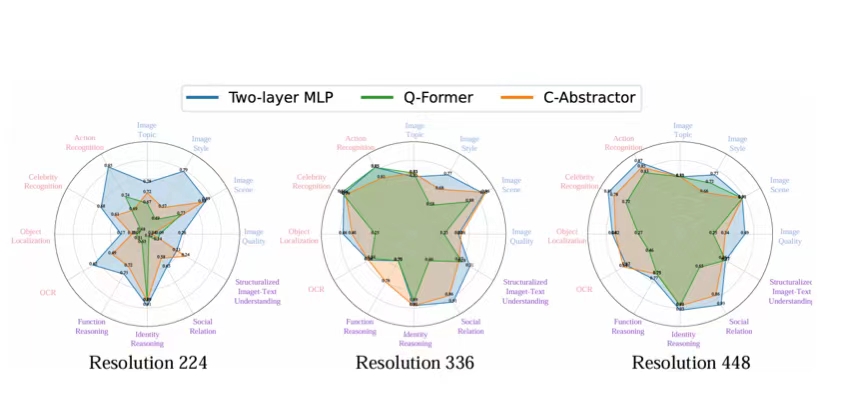
近年来,多模态大型语言模型(MLLMs)引起了产业界和学术界的广泛关注。根据融合位置的不同,MLLMs分为外部融合和内部融合架构,其中外部融合架构占主导地位。本文系统地探讨了连接器对MLLM性能的影响。具体而言,我们将连接器分为保留特征型和压缩特征型两类。通过统一的分类标准,我们将来自三个综合基准数据集(MMBench、MME、SEED-Bench)的子任务划分为粗粒度感知、细粒度感知和推理三种任务类型。
The Accuracy Paradox in RLHF: When Better Reward Models Don't Yield Better Language Models
arXiv preprint
·
09 Oct 2024
·
arxiv:2410.06554
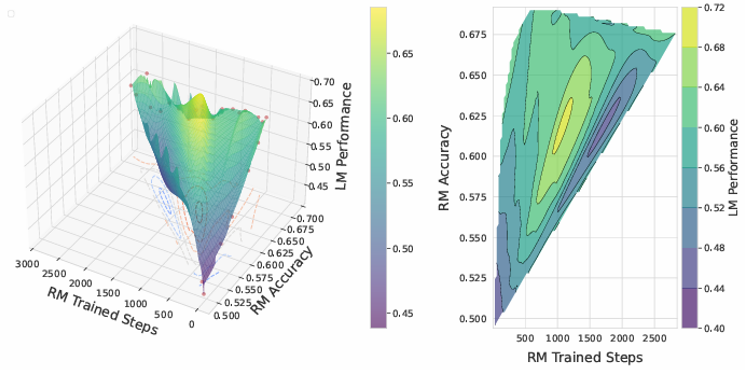
人类反馈强化学习显著提升了自然语言处理的效果,通过训练使语言模型更符合人类预期。本研究探讨了更强的奖励模型是否必然导致更优的语言模型表现。本文通过使用QA-FEEDBACK数据集和基于Longformer的奖励模型,针对相关性、事实性和完整性任务进行实验,揭示了一个令人惊讽的悖论:训练时使用中等准确率奖励模型的语言模型表现优于那些使用高准确率奖励模型的语言模型。
Deeper Insights Without Updates: The Power of In-Context Learning Over Fine-Tuning
arXiv preprint
·
04 Oct 2024
·
arxiv:2410.04691
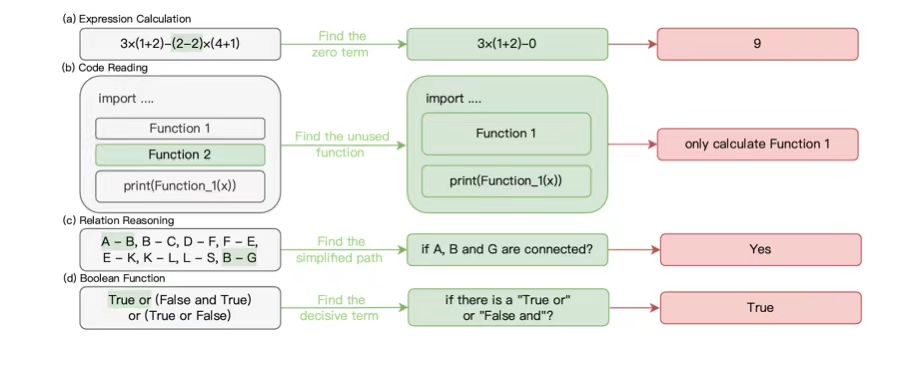
微调和上下文学习(ICL)是两种常用的为大型语言模型注入任务特定知识的方法。通常认为,微调由于可以基于训练数据调整模型的内部参数,在有足够样本的情况下会优于ICL。然而,本文提出了一个反直觉的发现:对于隐式模式任务,ICL能够显著优于微调捕捉这些模式。我们构建了多个包含隐式模式的数据集,例如通过奇偶性确定答案的序列或在计算中识别可约项。
Unveiling In-Context Learning: A Coordinate System to Understand Its Working Mechanism
arXiv preprint
·
17 Jul 2024
·
arxiv:2407.17011
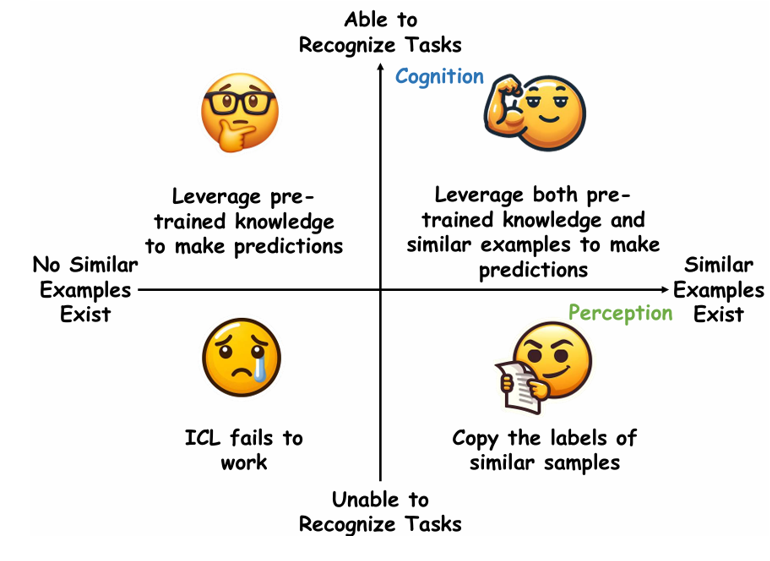
大型语言模型(LLMs)展现了显著的上下文学习(ICL)能力,然而其背后的工作机制仍未被充分理解。现有研究对ICL提出了两种相互矛盾的观点:一种强调演示中相似样本的重要性,指出标签正确性和更多示例的重要性;另一种则将ICL归因于LLM固有的任务识别能力,认为标签正确性和示例数量并非关键。在本研究中,我们提出了一个二维坐标系统,将这两种观点统一在一个系统框架中。

Assessing 'Implicit' Retrieval Robustness of Large Language Models
arXiv preprint
·
18 Jun 2024
·
arxiv:2406.18134
检索增强生成(Retrieval-augmented generation,RAG)作为一种通过外部知识增强大型语言模型的框架,近年来备受关注。然而,其有效性在很大程度上依赖于模型的检索稳健性。如果模型缺乏检索稳健性,其性能将受限于检索器的准确性,当检索到的上下文与任务无关时,模型表现可能大幅下降。在本文中,我们评估了不同大型语言模型的’隐式’检索稳健性,要求它们直接输出最终答案,而不显式判断检索到的上下文的相关性。
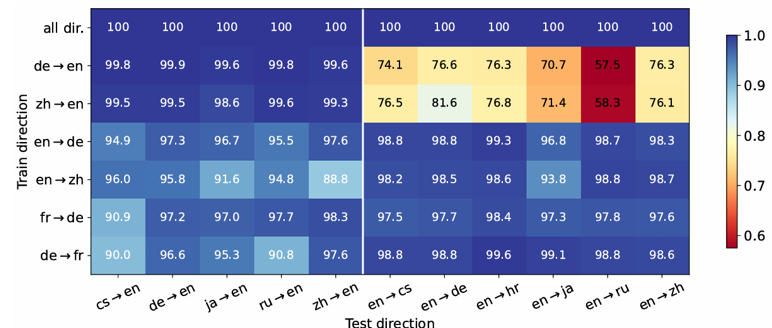
Fine-Tuning Large Language Models to Translate: Will a Touch of Noisy Data in Misaligned Languages Suffice?
arXiv preprint
·
22 Apr 2024
·
arxiv:2404.14122
传统上,多语言机器翻译的成功归因于训练数据的三个关键因素:大规模数据量、多样化的翻译方向以及高质量的数据。在当前微调大语言模型(LLMs)以进行翻译的实践中,我们重新审视了这些因素的重要性。我们发现,LLMs 在仅微调 32 对平行句子的情况下就表现出了强大的翻译能力,并且微调单一翻译方向能够实现多方向的翻译。
2023
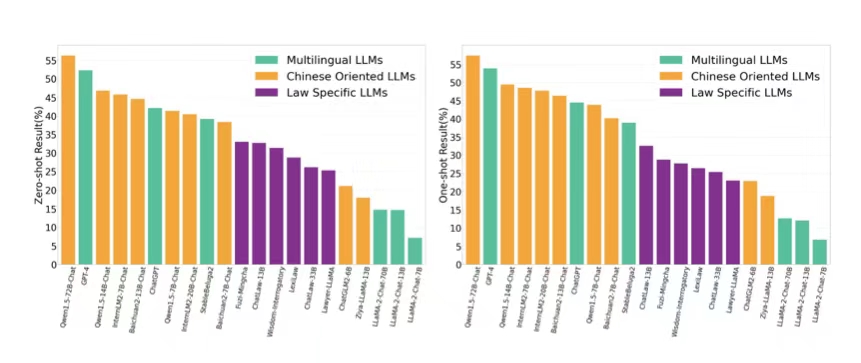
LawBench: Benchmarking Legal Knowledge of Large Language Models
arXiv preprint
·
16 Sep 2023
·
arxiv:2309.16289
我们提出了LawBench,这是第一个由20个任务组成的评估基准,旨在评估大型语言模型(LLMs)在处理中文法律相关任务中的表现。LawBench经过精心设计,能够从广泛接受的布卢姆认知分类法对应的三个认知层次上,精确评估LLMs的法律能力。利用LawBench,我们对21个热门LLMs进行了全面的评估,并首次对其实际表现进行了比较分析,揭示了它们的相对优势与劣势。
–>